Tagging is a popular way to organize stuff online (like videos and articles). People can add their own labels (tags) to things, which makes it easier to find them later. This is a simpler and cheaper way than having a giant list of pre-defined categories.
Tags are super helpful for search engines and recommendation systems (think finding things online or getting suggestions). They’re even better than titles, descriptions, or comments! That’s why some systems recommend tags to users. This helps people find the right tags and improves the overall search experience. This post will explain how tagging systems work and how these tag recommendations happen. A tag recommendation service can greatly aid the tagging process. Users using this kind of service are assisted in choosing some of the suggested tags or in creating new ones. In light of this, tag recommendation offers advantages beyond just enhancing user experience. For instance, there’s a good chance of raising the caliber of tags created by decreasing the frequency of misspellings and nondescriptive terms. Tag recommendation can therefore serve as an indirect means of enhancing the quality of IR services that use tags as data sources. The direct implementation of the suggested tags in search and on query expansion are two more instances of the advantages tag suggestion can offer IR services.

Tagging, also known as social bookmarking, is the process of attaching a pertinent word or phrase to an object (such as a document, picture, or video). The emergence of Web 2.0 apps like Del.icio.us1 and Flickr2, which facilitate social bookmarking on webpages and photos, respectively, has led to a surge in the popularity of tagging services among users and increased interest from the academic and industry sectors. By allowing users to annotate materials with keywords or tags, these websites let users organize and share resources with other people. Research into the application of data mining and machine learning techniques for automated tag recommendation of both text and digital material on the Web has gained attraction because of the practically limitless and free potential amount of tagged data that is available.

The automatic method of recommending informative and helpful tags to an emerging object based on past data is known as the “Problem Tag recommendation. Unless otherwise noted, we will concentrate on documents in this post, even if the objects to be tagged can also be photographs, videos, or other types of media. A tagged document is typically linked to one or more tags in addition to the people who annotated it with various tags. As a result, a triplet (u,d,t) can be used to describe the tagging action to a document d carried out by user u with tag t. While the relationship between tags themselves cannot be directly observed, it is evident that both the users and the documents are highly connected to the tags using a graph representation, where each node is one of the elements in the triplet and edges between nodes represent the degree of connection. As a result, the user or document perspectives are the only ways in which it is possible to suggest pertinent tags to new users or documents.
As demonstrated, there are two ways to approach tag recommendation: document-centered approaches and user-centered approaches.

The goal of user-centered techniques is to recommend tags to a user from comparable users or user groups by predicting the user’s interests based on their past tagging habits. However, by classifying documents into distinct categories, document-centered techniques concentrate on the analysis at the document level. It is presumed that documents belonging to the same topic will share more common tags than documents from different topics. Both models can theoretically be taught using conventional machine learning techniques. Collaborative filtering (CF) techniques, for instance, can be used to determine user interests for user-centered approaches.
Both supervised and unsupervised topic models (e.g., SVM and LDA topic models) are suitable options for classifying document subject groups in document-centered techniques. It should be noted that in order to incorporate both user-centered and document-centered techniques, researchers have recently presented dimension reduction methods in which the (user, item tag) triplets are handled as tensors.
Although both strategies sound reasonable, it comes out that the user-centered strategies are ineffective for a number of clear reasons. First, as per the findings of a research, only a very tiny percentage of users engage in intensive tagging, with the distribution of users vs. the number of tag applications following a long tail power law distribution. Furthermore, studies have demonstrated that although the vocabulary of tags is constantly expanding, their usefulness is rather low. Finding an appropriate model to perform efficient tag suggestion is challenging for user-centered techniques because of the comparatively small amount of user data that has been collected. Although the problem of sparseness can be partially mitigated by grouping users based on their interests, user-centered approaches are not very adaptable when it comes to tracking how user interests change over time.
Because the documents include extensive information, document-centered techniques are, in comparison, more robust.

Additionally, the underlying semantics of words and tags provide a possible connection between the subjects and contents of the documents; in the case of supervised learning, tags can be used as class labels for the documents, and in the case of unsupervised learning, summaries of the documents can be used as a learning approach. This means that any complex machine learning method can be used to the user-centered tag recommendation technique with flexibility.
Furthermore, the majority of the research that has already been done has been on effectiveness, even though both effectiveness and efficiency are necessary to guarantee the operation of the tagging services.
Proposed Method for Tag Recommendation:
Deep Dive into the Tag Recommendation process:
1. Machine Learning Goals:
- Reusable models: Ideally, this method wouldn’t require significant changes to be applied to different tasks involving document classification and tag recommendation. For instance, the core graph-based representation and learning framework could potentially be adapted for tasks like recommending products based on user reviews or categorizing news articles.
- Scalability: The method should be able to handle large datasets efficiently. The Lanczos algorithm used for matrix approximation is known for its ability to deal with massive matrices without requiring them to be stored entirely in memory. Similarly, spectral clustering techniques used for grouping documents and tags are generally scalable to large datasets.
- Effective results: The ultimate goal is for the model to recommend relevant and accurate tags for documents, regardless of the specific domain or application.
2. Proposed Method:
- Graph-based representation: The key idea is to capture the relationships between documents, tags, and words using a network structure called a bipartite graph. In a bipartite graph, there are two sets of nodes, and edges only connect nodes from different sets. Here, one set represents documents, and the other represents tags and words. The strength of the connection between a document and a tag (or word) can be represented by the weight of the edge connecting them. This allows the model to consider the context and co-occurrence of words and tags within documents.

3. Learning Framework:
- Two-stage framework:
- Offline learning stage: This is where the model is built using historical data. It involves tasks like approximating document-tag and word-tag relationships using the Lanczos algorithm, grouping documents and tags based on similarities (spectral clustering), ranking tags within each cluster, and finally learning the probability distribution of documents belonging to different classes using the Poisson mixture model.
- Online recommendation stage: This is where the trained model is used to make predictions on new documents. The model takes a new document as input, calculates its class probabilities, and recommends tags based on the joint probabilities between the document and relevant tags.
4. Offline Learning Stage – Specific Techniques:
- Lanczos algorithm: This is an iterative method used to approximate the largest eigenvalues and eigenvectors of a large, symmetric matrix. In this context, the matrix represents the weighted connections between documents and tags (or words). By approximating these key components, the algorithm can capture the essential relationships within the data without needing to store the entire massive matrix.
- Spectral recursive embedding (SRE): This technique leverages the information obtained from the Lanczos approximation to group documents and tags into clusters based on their similarities. The underlying idea is that documents and tags that frequently co-occur or share similar connections in the graph are likely to be related thematically. SRE helps identify these thematic clusters, which are then used for tag recommendation.
- Node ranking algorithm: Within each identified cluster, this algorithm assigns a score to each tag based on its importance or relevance. This helps prioritize tags when making recommendations. For example, a tag like “deep learning” might be ranked higher than a more general one like “artificial intelligence” within a cluster related to machine learning.
- Poisson mixture model (PMM): This is a statistical model used to learn the probability distribution of documents belonging to different classes (clusters in this case). The model assumes that the number of times a word appears in a document follows a Poisson distribution, and it learns the parameters of this distribution for each class. This allows the model to estimate the likelihood of a new document belonging to a particular class based on its word content.
5. Online Recommendation Stage – Putting it Together:
- New document input: The model receives a new document for which relevant tags need to be recommended. This document is typically represented as a vector of numerical values that capture its content.
- Class probabilities: Based on the learned model (including the document-tag relationships and class distributions), the model calculates the probability of the new document belonging to each pre-defined class (topic cluster).
- Tag recommendation: Using the calculated class probabilities and the joint probabilities between tags and the document, the model recommends the most relevant tags. This might involve considering factors like the ranking of tags within each relevant class and the overall strength of the connection between the document and each tag.
6. Advantages of Two-Way PMM:
- Multi-variate distribution modeling: PMM goes beyond simply counting word occurrences. It captures the complex relationships between words within each class. For instance, the model might learn that documents about “machine learning” are more likely to mention words like “neural networks” and “algorithms” together, compared to documents about “natural language processing.” This allows for more nuanced tag recommendations.
Approach:
Approach Breakdown with Example: Graph-based Tag Recommendation
This approach recommends tags for documents by analyzing the relationships between documents, tags, and words using a graph structure. Here’s a step-by-step explanation with an example:
Step 1: Building Bipartite Graphs and Topic Clusters
- Bipartite Graphs: Imagine two sets of nodes in a network:
- Documents (X): Each node represents a document (e.g., research paper, news article).
- Terms (Y): Each node represents a word or tag associated with the documents (e.g., “machine learning,” “algorithms”).
- Edges and Weights: Edges connect documents and terms, indicating their co-occurrence. The weight of an edge (wij) reflects how frequently a term (j) appears in a document (i). Higher weight signifies a stronger connection.
- Topic Clusters: The graph is then divided into smaller subgraphs, also called clusters. These clusters represent groups of documents and terms that are thematically similar. Imagine splitting the overall network into communities based on shared topics. For instance, one cluster might focus on “machine learning,” another on “natural language processing,” and so on.
Step 2: Normalization and Approximation Explained
This section dives into how the approach deals with large datasets and noisy data:
1. Normalization:
- Bias elimination: The weight matrix (W) representing document-term relationships might be biased due to varying document lengths (some documents might have more terms than others). Normalization aims to address this.
- Row normalization (simple but not ideal): A common approach is to normalize each row of W, essentially dividing each weight by the sum of weights in that row. This accounts for document length but ignores the symmetrical nature of the bipartite graph (documents and terms influence each other).
2. Normalized Laplacian for Normalization:
- Considering symmetry: This approach proposes using the normalized Laplacian matrix (L(W)) instead of simple row normalization. The Laplacian takes into account the symmetrical relationships between documents and terms in the graph.
- Formula for normalized Laplacian: The formula involves the degree of each vertex (number of connections) and the weights of edges. It essentially scales the weights based on the vertex’s overall connectivity.
3. Large-scale Datasets and Approximation:
- Challenge: When dealing with massive datasets (millions of documents and terms), directly using the Laplacian matrix becomes computationally expensive.
- Low-rank approximation: The approach proposes using a technique called the Lanczos algorithm to find a lower-dimensional representation of the normalized Laplacian matrix (denoted by ˜W). This reduces the computational cost significantly.
- Lanczos algorithm: This algorithm iteratively identifies the most important eigenvalues and eigenvectors of the Laplacian matrix. These capture the essential relationships within the data without needing to work with the entire massive matrix.
- Benefits of low-rank approximation:
- Lower computation cost: Processing the smaller ˜W is more efficient.
- Extracting correlations: The approximation focuses on the most significant connections between documents and terms.
- Noise reduction: The process can help remove irrelevant noise from the data.
In essence, this section explains how the approach tackles the challenges of large datasets by using normalization and approximation techniques to create a more efficient and effective representation of the relationships between documents, terms, and topics.
Step 3: Bipartite Graph Partitioning with Spectral Recursive Embedding (SRE)
This section describes how the approach divides the bipartite graph (documents and terms) into topic clusters using Spectral Recursive Embedding (SRE).
Traditional vs. Normalized Cut:
- Traditional methods: These algorithms aim to minimize the total weight of edges that are cut when dividing the graph into clusters. However, this can lead to unbalanced clusters with varying sizes.
- Normalized Cut (Ncut): This approach addresses the issue of unbalanced clusters. It considers not only the total weight of cut edges but also the density of connections within each cluster.
Ncut Formula:
The formula for Ncut s involves two key components:
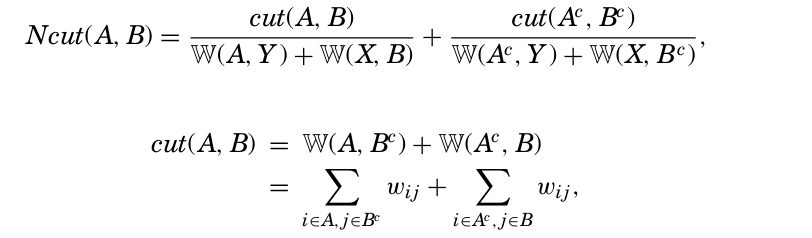
- Cut: This represents the sum of weights for edges connecting nodes from different clusters (think of misplaced connections). It’s calculated in two ways:
cut(A, B): Sum of weights for edges between nodes in set A of one cluster and nodes in set B of another cluster.cut(Acomplement, Bcomplement): Similar calculation for the complementary sets (nodes not in A or B).
- Weight of connections to the entire graph: This considers the total connection strength of each cluster to all terms (Y) and all documents (X). It ensures clusters are well-connected internally.
Rationale behind Ncut:
- Ncut aims to find partitions that:
- Minimize the cut (reduce the number of misplaced connections between clusters).
- Maximize the within-cluster density (ensure documents and terms within a cluster are well-connected).
Benefits for Tagging Documents:
- By using Ncut for partitioning, the approach aims to create clusters where documents within a cluster are likely to be related to a specific topic.
- Denser clusters with strong internal connections improve the effectiveness of tag recommendation. Relevant documents and their associated tags are more likely to be grouped together.
Spectral Recursive Embedding (SRE):
The passage mentions using SRE to achieve the partitioning based on the Ncut criteria. SRE is an algorithm that leverages the information from the normalized Laplacian matrix (obtained through normalization and approximation) to identify these optimal partitions based on Ncut. It essentially performs a recursive division of the graph into smaller subgraphs, each representing a thematically coherent cluster.
Example:
Consider a document about “deep learning” that mentions terms like “neural networks,” “convolutional neural networks,” and “backpropagation” frequently. It might also mention “artificial intelligence” and “algorithms” less frequently.
- In the bipartite graph, there would be a strong connection (high weight) between the document node and terms like “neural networks” and “convolutional neural networks.”
- Weaker connections might exist with “artificial intelligence” and “algorithms.”
- The document might be grouped within a cluster containing other documents and terms related to “deep learning.”
Step 2: Ranking Tags within Clusters
- Importance Score: Within each identified topic cluster, each tag is assigned a score based on its importance or relevance to the documents within the cluster. This helps prioritize tags when making recommendations.
- Example: In the “deep learning” cluster, the tag “neural networks” might receive a higher score than a more general tag like “artificial intelligence.”
Step 3: Training a Two-Way Poisson Mixture Model (PMM)
- Document Classification: This step involves training a statistical model called PMM. The model analyzes the word distribution within documents and learns the probability of a document belonging to a specific topic cluster (based on the terms it contains).
- Example: The PMM might learn that documents with frequent mentions of “neural networks” and “backpropagation” are more likely to belong to the “deep learning” cluster.
Step 4: Soft Classification and Tag Recommendation
- New Document Input: When a new document arrives, the model analyzes its content and estimates the likelihood of it belonging to each pre-defined topic cluster based on the trained PMM.
- Tag Recommendation: Considering the class probabilities and the relationship between tags and documents within each cluster, the model recommends tags with the highest overall probability of being relevant to the new document.
Overall, this graph-based method leverages the relationships between documents, terms, and clusters to make informed tag recommendations.